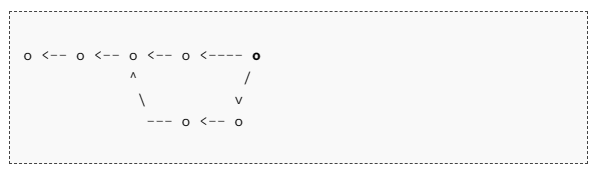
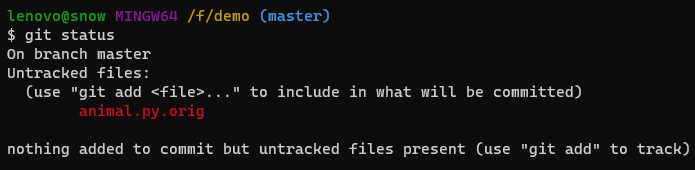
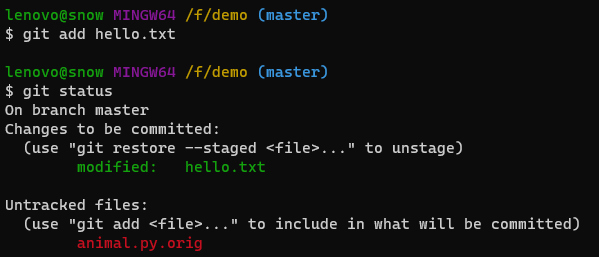
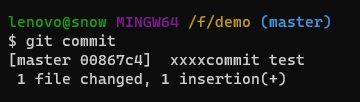
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
#include <iostream>
using namespace std;
int count = 0;
int boardsize = 1;
int Board[8][8];
void Cover(int tr, int tc, int dr, int dc, int size);
void OutputBoard(int size);
int main()
{
int x, y;
int i;
int k;
cout << "请确认棋盘规模,输入k大小(2k×2k):" << endl;
cin >> k;
for (i = 1; i <= k; i++)
boardsize *= 2;
cout << "请输入残缺棋子位置(行号,列号):" << endl;
cin >> x >> y;
Cover(0, 0, x, y, boardsize);
OutputBoard(boardsize);
}
void Cover(int tr, int tc, int dr, int dc, int size)
{
if (size < 2)
return;
int t = count++;
int s = size / 2;
if (dr < tr + s && dc < tc + s)
{
Cover(tr, tc, dr, dc, s);
Board[tr + s - 1][tc + s] = t;
Board[tr + s][tc + s - 1] = t;
Board[tr + s][tc + s] = t;
Cover(tr, tc + s, tr + s - 1, tc + s, s);
Cover(tr + s, tc, tr + s, tc + s - 1, s);
Cover(tr + s, tc + s, tr + s, tc + s, s);
}
else if (dr < tr + s && dc >= tc + s)
{
Cover(tr, tc + s, dr, dc, s);
Board[tr + s - 1][tc + s - 1] = t;
Board[tr + s][tc + s - 1] = t;
Board[tr + s][tc + s] = t;
Cover(tr, tc, tr + s - 1, tc + s - 1, s);
Cover(tr + s, tc, tr + s, tc + s - 1, s);
Cover(tr + s, tc + s, tr + s, tc + s, s);
}
else if (dr >= tr + s && dc < tc + s)
{
Cover(tr + s, tc, dr, dc, s);
Board[tr + s - 1][tc + s - 1] = t;
Board[tr + s - 1][tc + s] = t;
Board[tr + s][tc + s] = t;
Cover(tr, tc, tr + s - 1, tc + s - 1, s);
Cover(tr, tc + s, tr + s - 1, tc + s, s);
Cover(tr + s, tc + s, tr + s, tc + s, s);
}
else if (dr >= tr + s && dc >= tc + s)
{
Cover(tr + s, tc + s, dr, dc, s);
Board[tr + s - 1][tc + s - 1] = t;
Board[tr + s - 1][tc + s] = t;
Board[tr + s][tc + s - 1] = t;
Cover(tr, tc, tr + s - 1, tc + s - 1, s);
Cover(tr, tc + s, tr + s - 1, tc + s, s);
Cover(tr + s, tc, tr + s, tc + s - 1, s);
}
}
void OutputBoard(int size)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
cout.width(5);
cout << Board[i][j];
}
cout << endl;
}
}
|